Unsupervised Domain Adaptation via Structurally Regularized Deep Clustering
|
South China University of Technology1
|
Teaser
|
|
|
To address a potential issue of damaging the intrinsic data discrimination by explicitly learning domain-aligned features,
we propose a source-regularized, deep discriminative clustering method in order to directly uncover the intrinsic discrimination among target data,
termed as Structurally Regularized Deep Clustering (SRDC).
In SRDC, we also design useful ingredients to enhance target discrimination with clustering of intermediate network features,
and to enhance structural regularization with soft selection of less divergent source examples.
|
Abstract
|
Unsupervised domain adaptation (UDA) is to make predictions for unlabeled data on a target domain,
given labeled data on a source domain whose distribution shifts from the target one.
Mainstream UDA methods learn aligned features between the two domains,
such that a classifier trained on the source features can be readily applied to the target ones.
However, such a transferring strategy has a potential risk of damaging the intrinsic discrimination of target data.
To alleviate this risk, we are motivated by the assumption of structural domain similarity,
and propose to directly uncover the intrinsic target discrimination via discriminative clustering of target data.
We constrain the clustering solutions using structural source regularization that hinges on our assumed structural domain similarity.
Technically, we use a flexible framework of deep network based discriminative clustering
that minimizes the KL divergence between predictive label distribution of the network and an introduced auxiliary one;
replacing the auxiliary distribution with that formed by ground-truth labels of source data
implements the structural source regularization via a simple strategy of joint network training.
We term our proposed method as Structurally Regularized Deep Clustering (SRDC),
where we also enhance target discrimination with clustering of intermediate network features,
and enhance structural regularization with soft selection of less divergent source examples.
Careful ablation studies show the efficacy of our proposed SRDC.
Notably, with no explicit domain alignment, SRDC outperforms all existing methods on three UDA benchmarks.
|
Background & Motivation
|
|
|
The success of deep learning relies on a large amount of training data.
However, collecting and annotating data for all domains and tasks is extremely expensive and time-consuming.
We can utilize data from a label-rich source domain to solve the task on a label-scarce target domain.
But there is a distribution discrepancy between the source and target data.
So the model trained on source data cannot be readily applied to target data.
How to address this issue? Unsupervised domain adaptation (UDA)!
|
|
|
|
(a) Illustration of the assumption of structural domain similarity, including two concepts: domain-wise discrimination and class-wise closeness.
The orange line denotes the classifier trained on the labeled source data and the green one denotes the classifier trained on the labeled target data, i.e. the oracle target classifier.
(b) Illustration of damaging intrinsic structures of data discrimination on the target domain by the existing transferring strategy.
The dashed line denotes the source classifier adapting to the damaged discrimination of target data, which has a sub-optimal generalization.
(c) Illustration of our proposed uncovering strategy. Discriminative target clustering with structural source regularization uncovers intrinsic target discrimination.
Mainstream UDA methods take the transferring strategy of learning aligned features across domains,
which has a potential risk of damaging the intrinsic discrimination of target data, resulting in a sub-optimal generalization.
Based on our assumed structural domain similarity, we directly uncover the intrinsic target discrimination via discriminative clustering of target data
and constrain the clustering solutions using structural source regularization, leading to an adapted classifier closer to the oracle target classifier.
|
Highlights
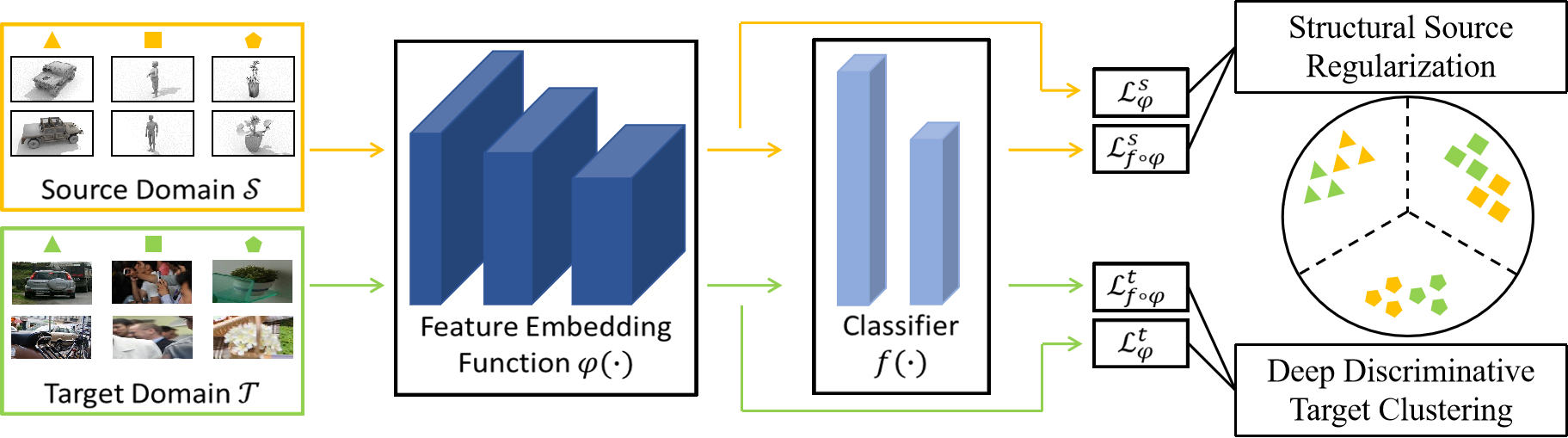
Deep Discriminative Target Clustering
|
We propose to use deep discriminative target clustering in the output space and feature space at the same time. This is a new dual clustering framework.
The clustering algorithm obtains pseudo labels of target data to supervise the model training by minimizing an objective of two terms.
The first term is the KL divergence between the network prediction label distribution and the introduced auxiliary distribution;
the second term is a regularization of cluster size balance.
Here, category prediction probability modeling in feature space is based on Euclidean distance from instance to learnable cluster centers.
The clustering behavior in feature space can not only further reveal the inherent differences between target data,
but also act as the constraint of clustering in output space to maintain different cluster centers and avoid mode collapse.
|
Structural Source Regularization
|
Based on the structural similarity between the source and target domains indicated by the UDA assumption,
we propose the structural source regularization — replacing the auxiliary distribution with truth label distribution,
and using the labeled source data to train the same classifier network layers, namely joint network training.
In addition, we propose a soft selection strategy for source samples,
which weights the source samples according to their importance to the target domain.
The concept of class-wise closeness in the assumption of structural domain similarity implies that
different source instances may have different regularization effects;
accordingly, they can be weighted based on distances to corresponding target clusters.
|
Training Algorithm
Experiments
Ablation Study and Learning Analysis
|
R1: Ablation Study
In the following table, we can observe that when any one of our designed components is removed, the performance degrades,
verifying that (1) both feature discrimination and structural source regularization are effective for improving target clustering;
(2) the proposed soft source sample selection scheme leads to better regularization.
|
R2: Source Refinement
In the following figure, we can observe that the source images with a canonical viewpoint have the higher weights than those with top-down, bottom-up, and side viewpoints,
which is intuitive since all target images are shown only from a canonical viewpoint.
The observation affirms the rationality of our proposed soft source sample selection scheme.
The images on the left are randomly sampled from the target domain Amazon and
those on the right are the top-ranked (the 3rd column) and bottom-ranked (the 4th column) samples from the source domain Webcam for three classes.
Note that the red numbers are the computed source weights.
|
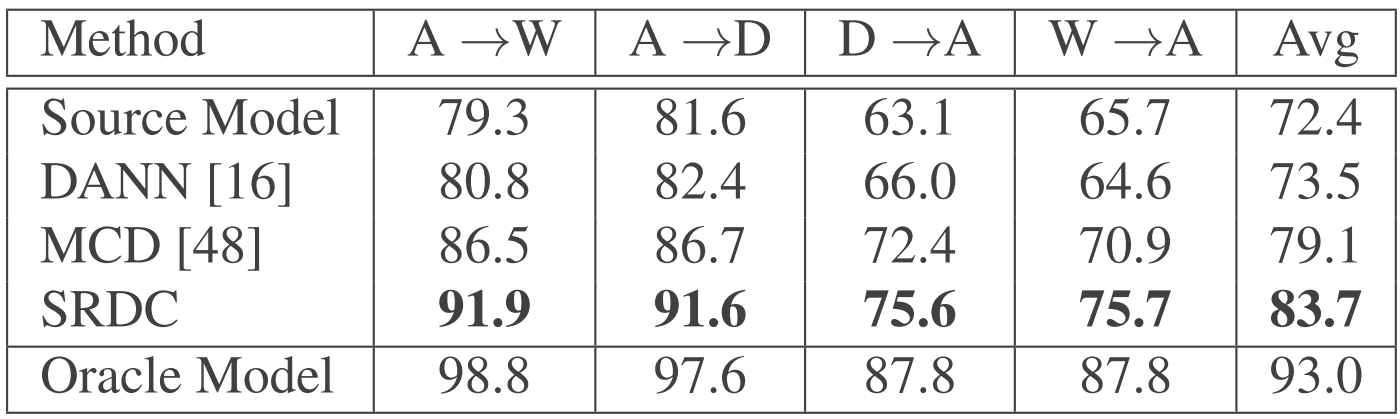
R3: Comparison under Inductive UDA Setting
In the following table, we can see that our proposed uncovering strategy SRDC achieves closer results to Oracle Model,
verifying the motivation of this work and the efficacy of our proposed SRDC.
|
R4: Feature Visualization
In the following figure, We can qualitatively observe that compared to Source Model,
the target domain features can be much better discriminated by SRDC,
which is based on data clustering to uncover the discriminative data structures.
The t-SNE visualization of embedded features on the target domain.
|
R5: Confusion Matrix
In the following figure, we can observe quantitative improvements from Source Model to SRDC, further confirming the advantages of SRDC.
The confusion matrix on the target domain.
|
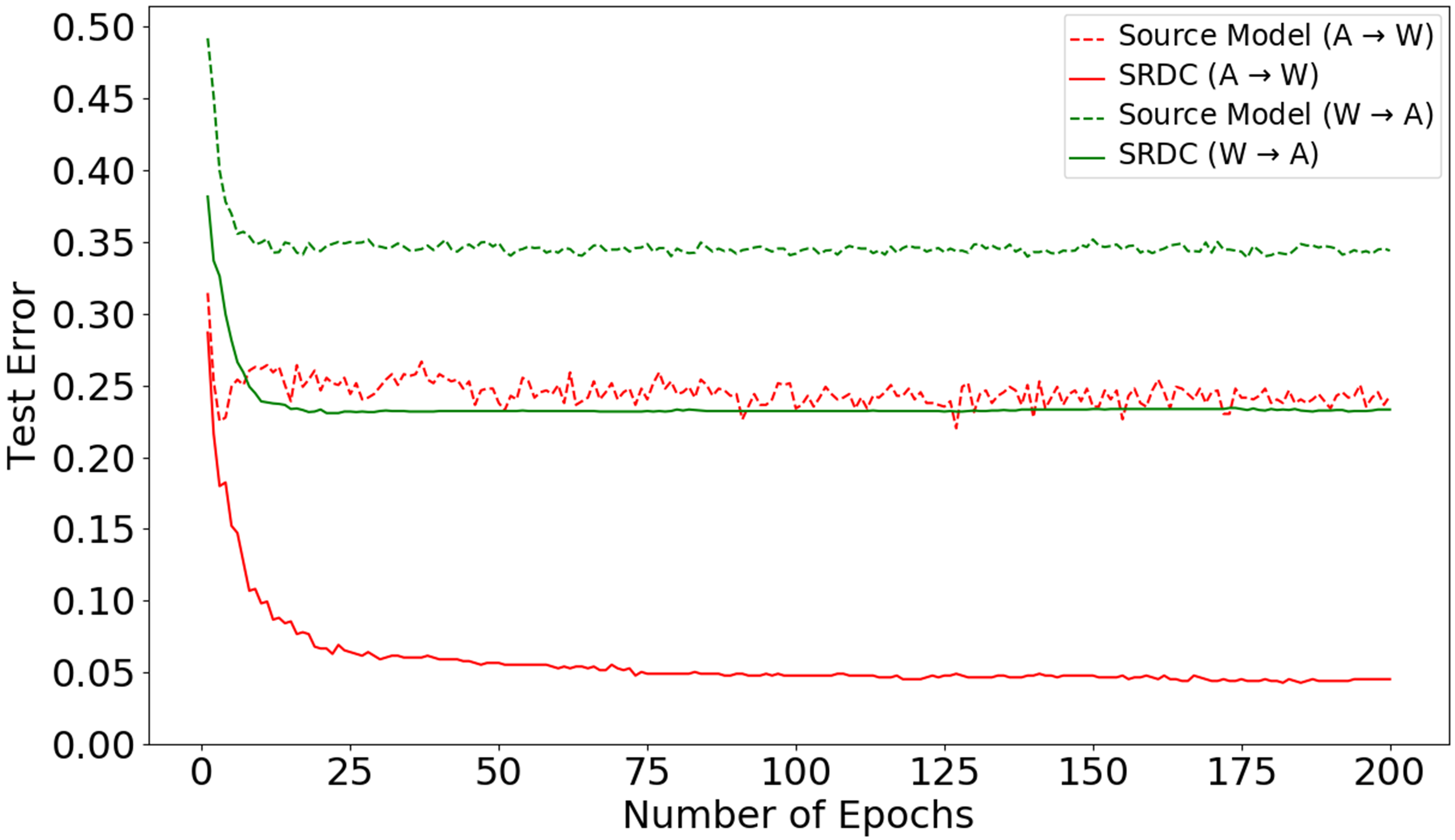
R6: Convergence Performance
In the following figure, We can observe that SRDC enjoys faster and smoother convergence performance than Source Model.
|
Comparison with SOTA
|
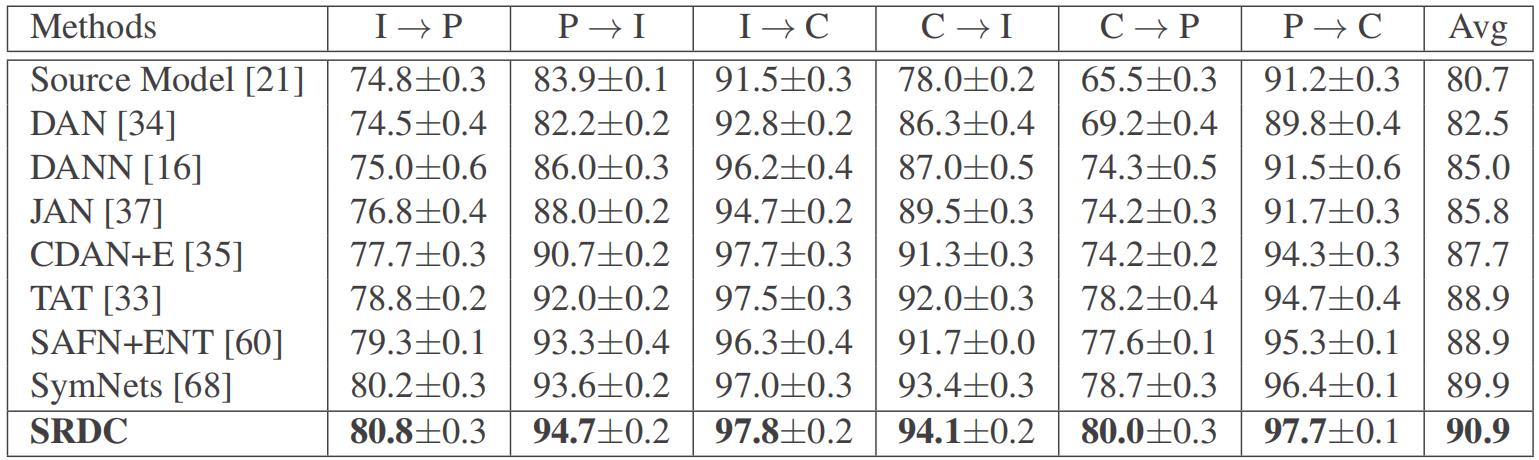
Notably, with no explicit domain alignment, our proposed SRDC outperforms all existing methods on three UDA benchmark datasets.
Results (%) on Office-31 (ResNet-50).
Results (%) on ImageCLEF-DA (ResNet-50).
Results (%) on Office-Home (ResNet-50).
|
BibTeX
@inproceedings{tang2020unsupervised,
title={Unsupervised domain adaptation via structurally regularized deep clustering},
author={Tang, Hui and Chen, Ke and Jia, Kui},
booktitle={Proceedings of the IEEE/CVF conference on computer vision and pattern recognition},
pages={8725--8735},
year={2020}
}
Acknowledgements
Based on a template by Keyan Chen.