|
To solve the basic and important problems in the context of image classification, such as the lack of comprehensive synthetic data research and the insufficient exploration of synthetic-to-real transfer, we in this paper propose to exploit synthetic datasets to explore questions on model generalization, benchmark pre-training strategies for domain adaptation (DA), and build a large-scale benchmark dataset S2RDA for synthetic-to-real transfer, which can push forward future DA research.
Specifically, we make the following contributions:
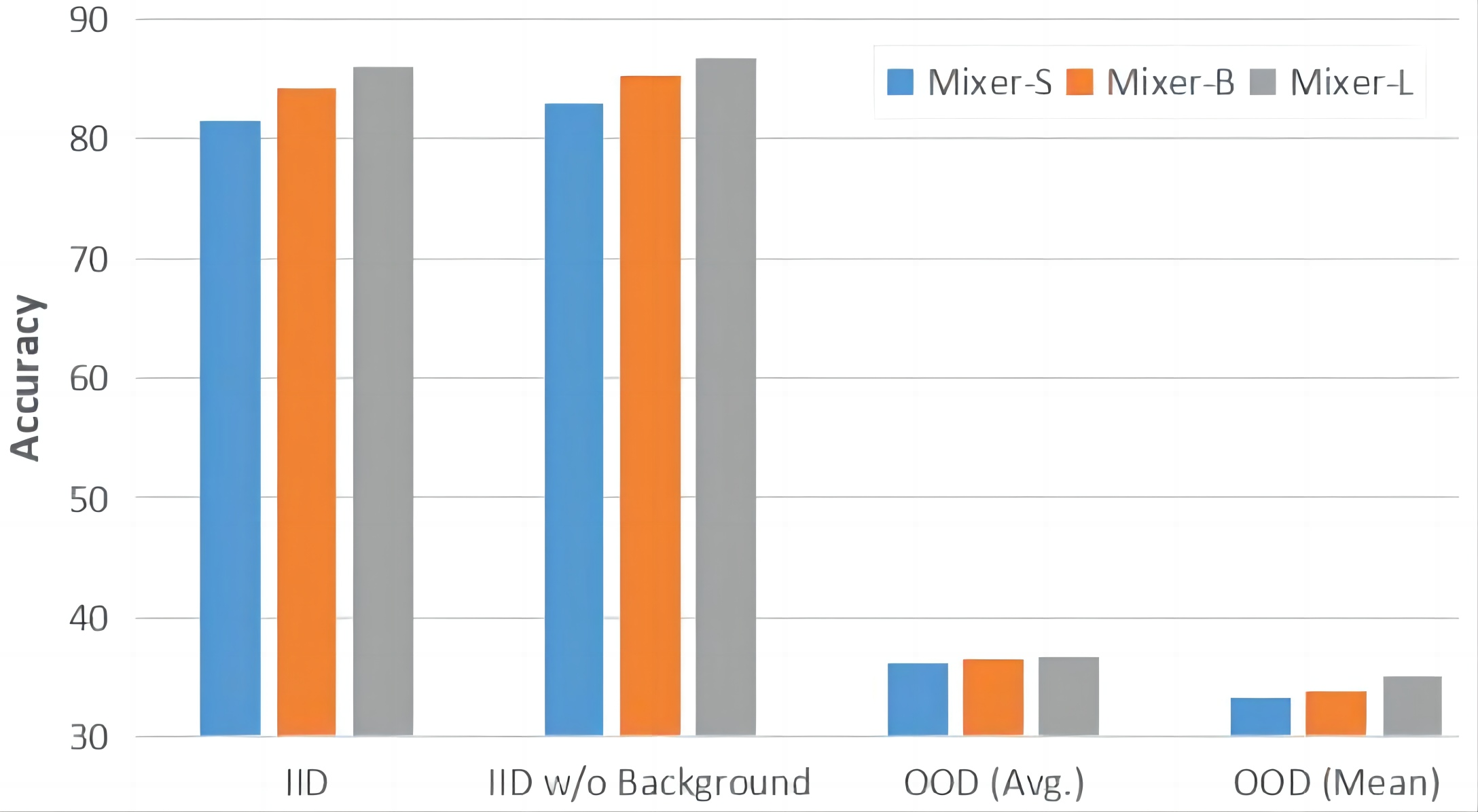
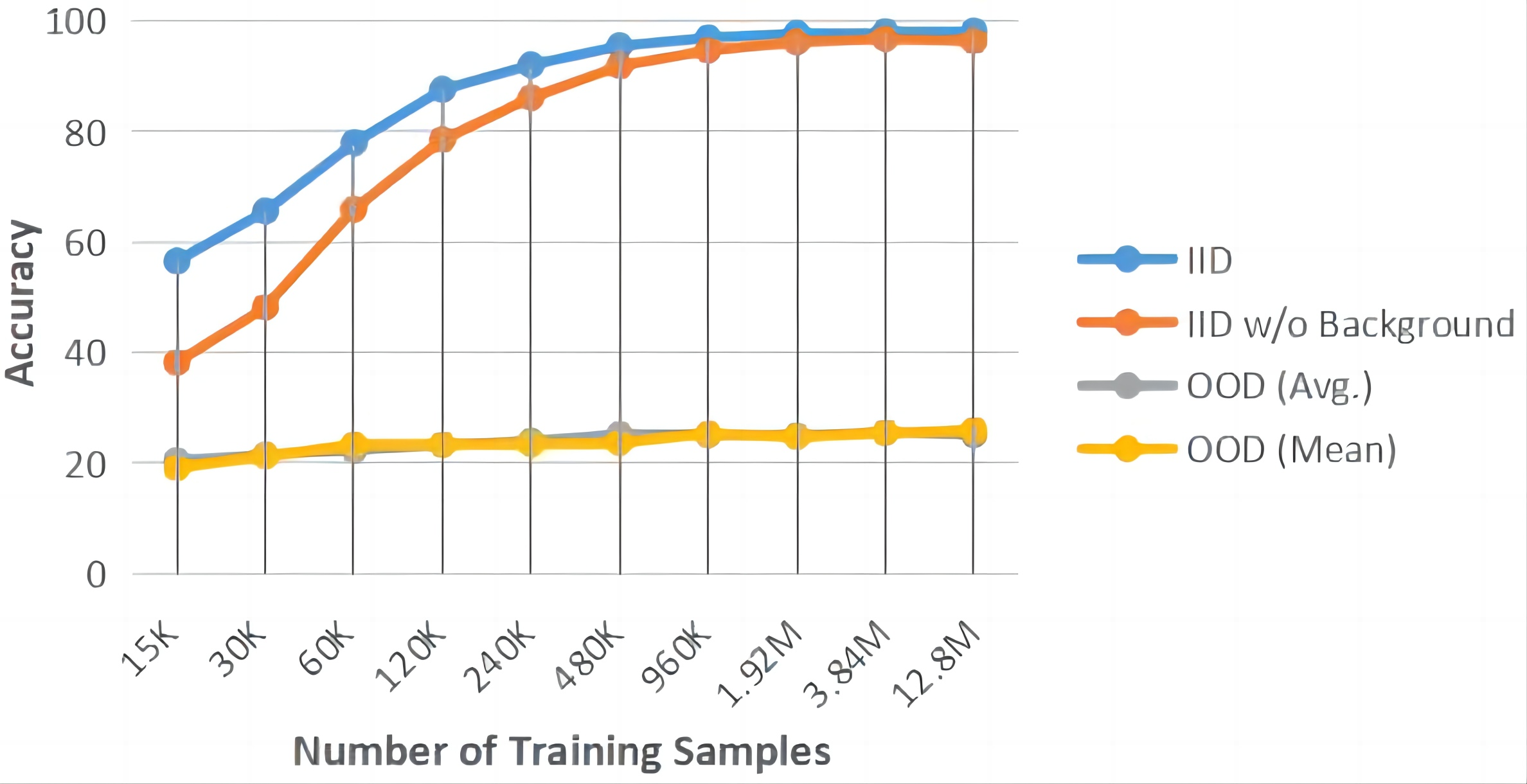
(i) under the well-controlled, IID data setting enabled by 3D rendering, we systematically verify the typical, important learning insights, e.g., shortcut learning, and discover the new laws of various data regimes and network architectures in generalization;
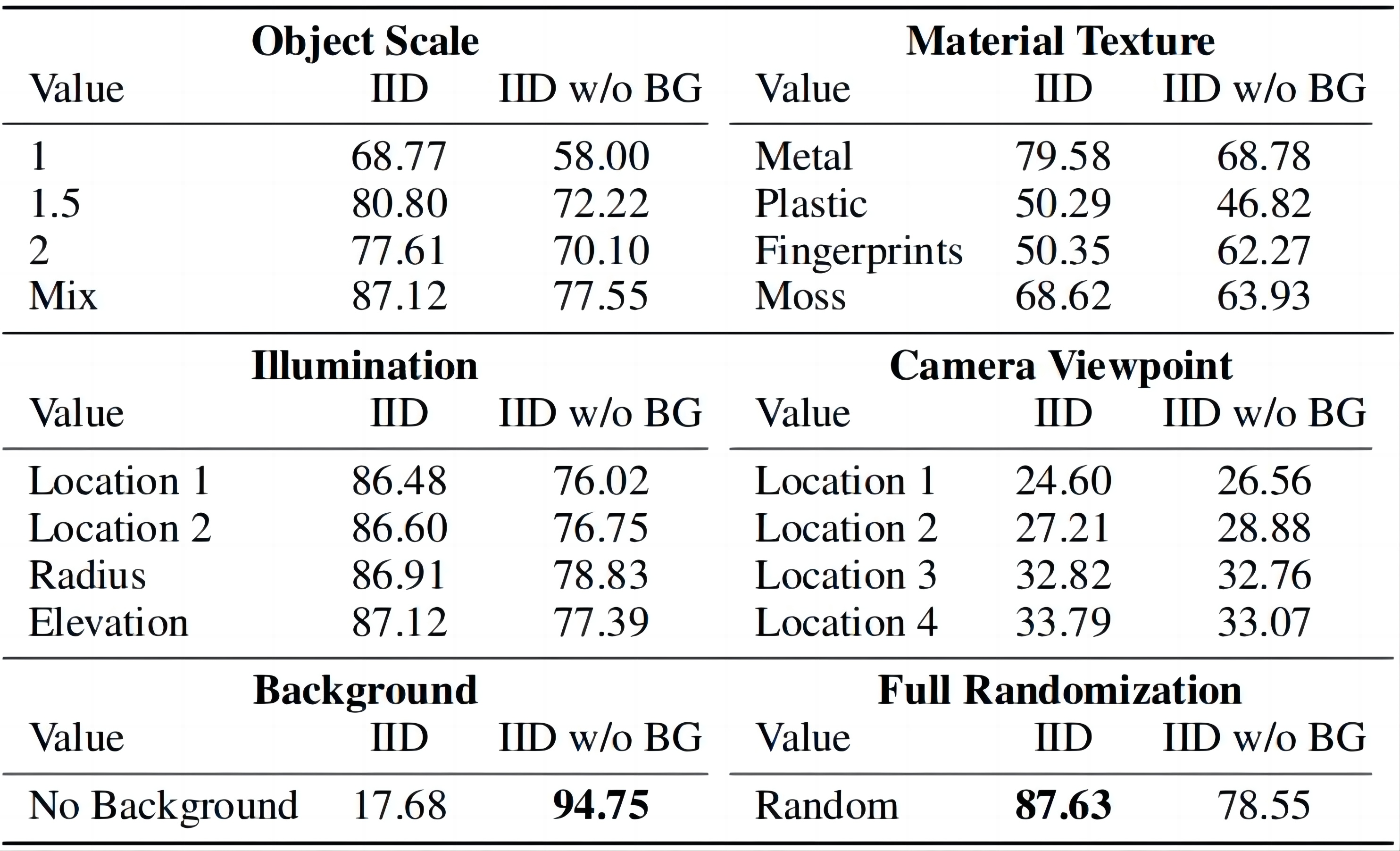
(ii) we further investigate the effect of image formation factors on generalization, e.g., object scale, material texture, illumination, camera viewpoint, and background in a 3D scene;
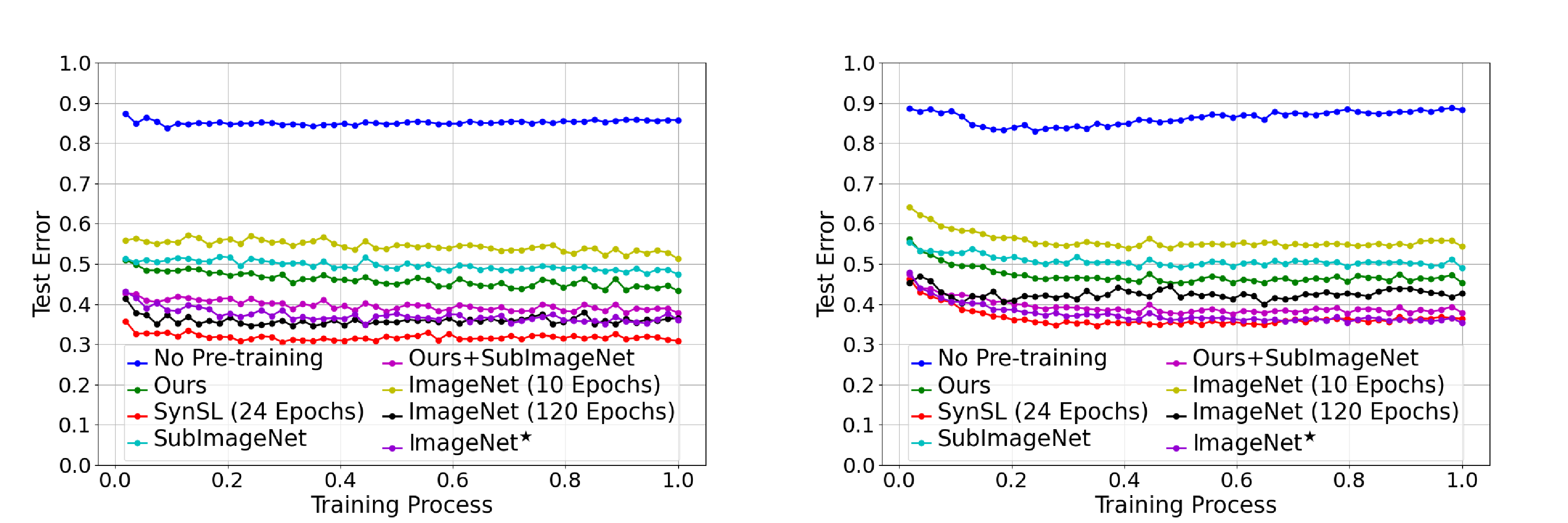
(iii) we use the simulation-to-reality adaptation as a downstream task for comparing the transferability between synthetic and real data when used for pre-training, which demonstrates that synthetic data pre-training is also promising to improve real test results;
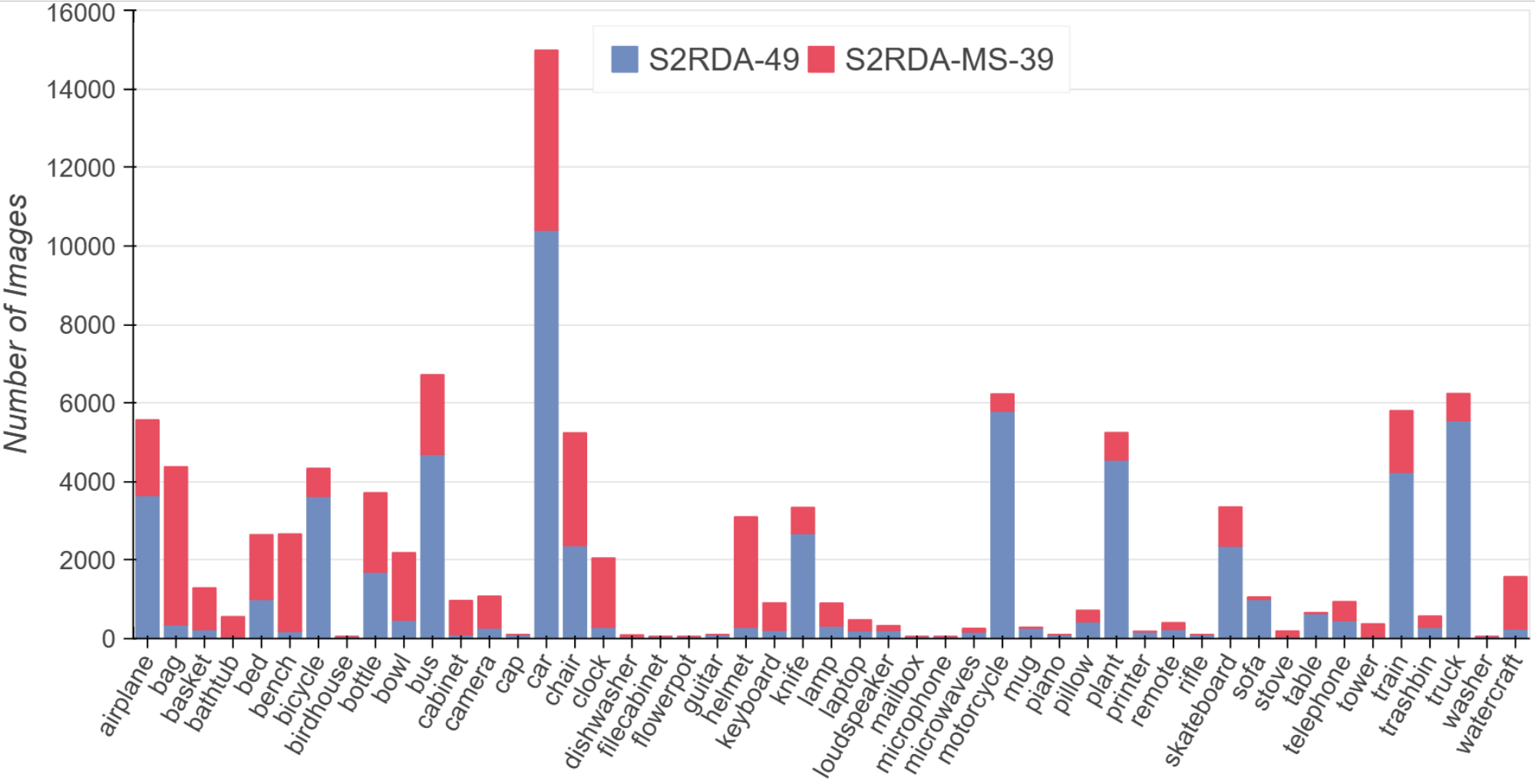
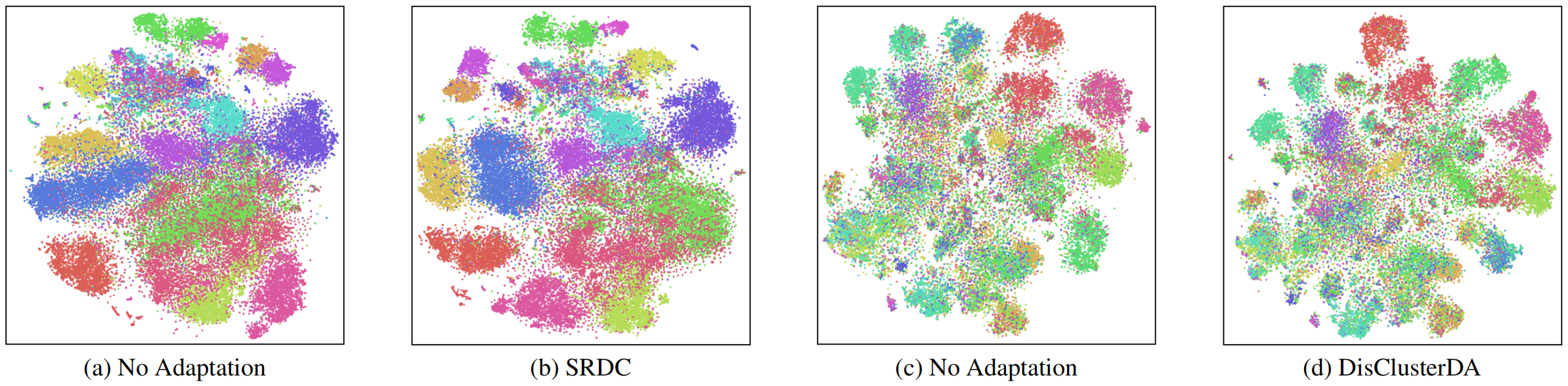
finally, (iv) we develop a new large-scale synthetic-to-real benchmark for image classification, termed S2RDA, which provides more significant challenges for transfer from simulation to reality.
|